Concepts:
- Thread:
- One tiny worker that does a small part of the job.
- Example: One thread could add just one element of two arrays.
- Block:
- A group of threads.
- Threads inside a block can cooperate (share data, synchronize).
- Example: A block might have 256 threads, each working on a small piece.
- Grid:
- A group of blocks.
- The entire GPU program launches a grid of blocks, so the work is distributed widely.
- Example: 100 blocks, each with 256 threads.
- threadIdx:
- Every thread has a thread ID inside its block.
threadIdx.xtells you which thread you are (within the block).
- blockIdx:
- Every block has a block ID inside the grid.
blockIdx.xtells you which block you are.
- blockDim:
- Tells you how many threads are in a block (the block’s size).
blockDim.xis the number of threads per block.
Very Simple Simulation Example
Suppose you have two arrays:A = [1, 2, 3, 4, 5, 6, 7, 8] B = [10, 20, 30, 40, 50, 60, 70, 80]
You want to add them element by element and get C[i] = A[i] + B[i].
Imagine:
- 2 blocks
- 4 threads per block
Thus:
- Total threads = 2 × 4 = 8 threads (good, we have 8 elements).
Each thread will do one addition.
Now look how each thread figures out its global index:
int global_index = blockIdx.x * blockDim.x + threadIdx.x;
Where:
blockIdx.x= block number (0 or 1)blockDim.x= 4 (threads per block)threadIdx.x= thread number within the block (0, 1, 2, or 3)
Mapping:
So thread (block 0, thread 0) adds A[0] + B[0],
thread (block 1, thread 2) adds A[6] + B[6], and so on.
CUDA Code Sketch:
__global__ void add_vectors(int *A, int *B, int *C) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
C[idx] = A[idx] + B[idx];
}
When you call the kernel:
add_vectors<<<2, 4>>>(A, B, C);
- 2 blocks
- 4 threads each
- All elements get processed in parallel.
Final simple picture:
- Threads are workers.
- Blocks are teams of workers.
- Grid is the whole construction site.
threadIdx,blockIdx,blockDimare the address system that tells each worker what piece of the job they must do.

Exercises:
1. If we want to use each thread in a grid to calculate one output element of a vector addition, what would be the expression for mapping the thread/block indices to the data index (i)?
Answer: i=blockIdx.xblockDim.x + threadIdx.x;
2. Assume that we want to use each thread to calculate two adjacent elements of a vector addition. What would be the expression for mapping the thread/block indices to the data index (i) of the first element to be processed by a thread?
Answer: i=(blockIdx.xblockDim.x + threadIdx.x)*2
Explanation: So the question basically asks that each thread “i” will process 2 consecutive elements in a vector. For example if a vector has 6 elements and we use 3 threads to process them, thread 0 will process elements 0 and 1 of the vector, while the thread 1 will process the elements 2 and 3, thread 2 will process elements 4 and 5 and so forth.

__global__ void vecAddKernel(float* A, float* B, float* C, int n){
int i = (threadIdx.x + blockDim.x * blockIdx.x) * 2;
if (i < n){
C[i] = A[i] + B[i];
C[i + 1] = A[i + 1] + B[i + 1];
}
}3. We want to use each thread to calculate two elements of a vector addition.
Each thread block processes 2*blockDim.x consecutive elements that form
two sections. All threads in each block will process a section first, each
processing one element. They will then all move to the next section, each
processing one element. Assume that variable i should be the index for the
first element to be processed by a thread. What would be the expression for
mapping the thread/block indices to data index of the first element?
Answer: i=blockIdx.xblockDim.x2 + threadIdx.x;
Explanation: Let blockDim.x = 2 (i.e., 2 threads per block)
So, each block processes 2 * 2 = 4 elements.
Let the vector have 8 elements. So, element 0->3 is section 1 and element 4->7 is section 2.
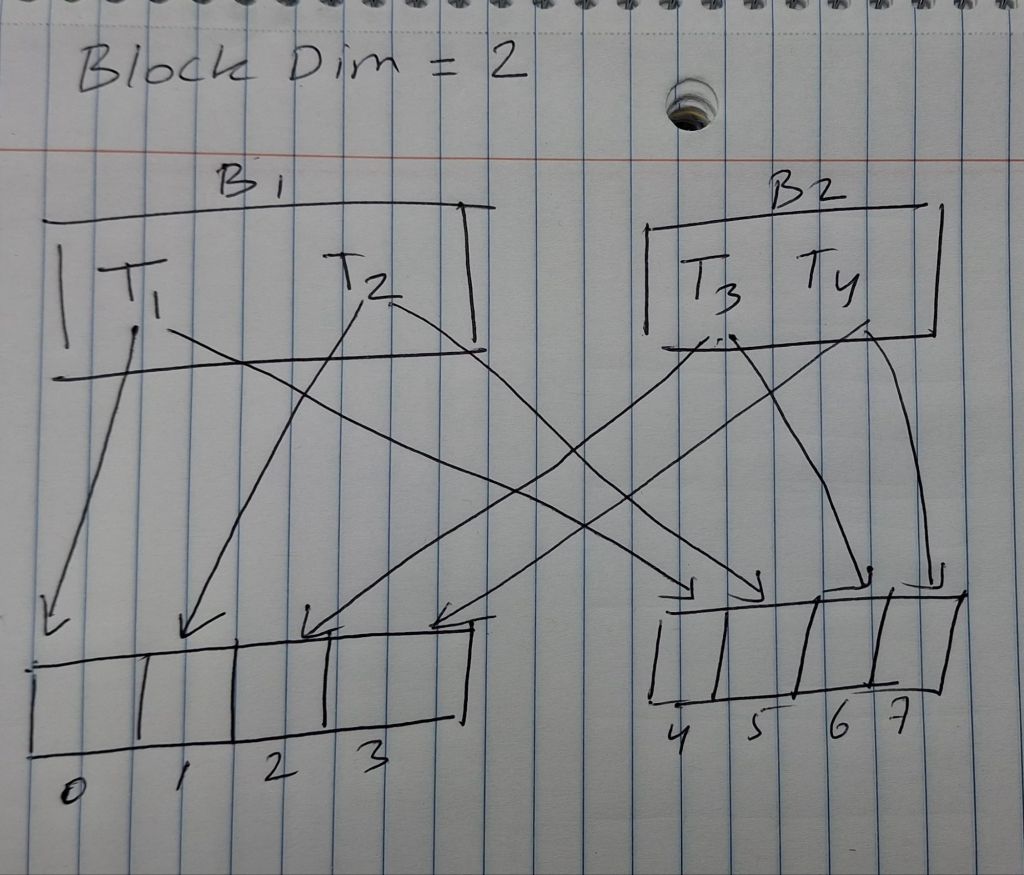
// Imagine blockIdx.x = 0, blockDim.x=256 and threadIdx.x = 0; then i = 0;
// if blockIdx.x = 1 then i becomes 1 * 256 * 2 + 0 = 512;
// Meaning all the elements before 512 were processed by blockIdx.x = 0;
__global__ void vecAddKernel(float* A, float* B, float* C, int n){
int i = blockDim.x * blockIdx.x * 2 + threadIdx.x;
if (i < n){
C[i] = A[i] + B[i]; // Imagine i = 0, then indexing here is 0
}
int j = i + blockDim.x;
if (j < n){
C[j] = A[j] + B[j];
}
}4. For a vector addition, assume that the vector length is 8000, each thread
calculates one output element, and the thread block size is 1024 threads. The
programmer configures the kernel call to have a minimum number of thread
blocks to cover all output elements. How many threads will be in the grid?
Answer: 8192.
Explanation: Each block has 1024 threads. Minimum number of blocks required to cover 8000 elements is (8000/1024 = 7.8125) but we can’t have 7.8125 blocks so we round up to 8 blocks with 1024 threads each amounts to 8192.
5. If we want to allocate an array of v integer elements in the CUDA device
global memory, what would be an appropriate expression for the second
argument of the cudaMalloc call?
Answer: v * sizeof(int)
Explanations:
cudaMalloc ( void** devPtr, size_t size );
devPtr: A pointer to the device memory pointer.
size: Number of bytes to allocate.
6. If we want to allocate an array of n floating-point elements and have a
floating-point pointer variable A_d to point to the allocated memory, what
would be an appropriate expression for the first argument of the cudaMalloc
Answer: (void **) &A_d
7. If we want to copy 3000 bytes of data from host array A_h (A_h is a pointer
to element 0 of the source array) to device array A_d (A_d is a pointer to
element 0 of the destination array), what would be an appropriate API call
for this data copy in CUDA?
Answer: cudaMemcpy(A_d, A_h, 3000, cudaMemcpyHostToDevice);
8. How would one declare a variable err that can appropriately receive the
returned value of a CUDA API call?
Answer: cudaError_t err;
9. Consider the following CUDA kernel and the corresponding host function
that calls it:
__global__ void foo_kernel(float* a, float* b, unsigned int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
b[i] = 2.7f * a[i] - 4.3f;
}
}
void foo(float* a_d, float* b_d) {
unsigned int N = 200000;
unsigned int threadsPerBlock = 128;
unsigned int blocks = (N + threadsPerBlock - 1) / threadsPerBlock;
foo_kernel<<<blocks, threadsPerBlock>>>(a_d, b_d, N);
}a. What is the number of threads per block?
Answer: 128
b. What is the number of threads in the grid?
Answer: 200064
c. What is the number of blocks in the grid?
Answer: 1563
d. What is the number of threads that execute the code on line 02?
Answer: 200064
e. What is the number of threads that execute the code on line 04?
Answer: 200000 because i<N filters 64 threads
f. A new summer intern was frustrated with CUDA. He has been complaining
that CUDA is very tedious. He had to declare many functions that he plans
to execute on both the host and the device twice, once as a host function and
once as a device function. What is your response?
Answer: host device indicates the function can be run on both the CPU and GPU, therefore intern doesn’t need to define the function two times.

Leave a comment